Background
Differentiating musculoskeletal symptoms is an actual and high impact problem.
Musculoskeletal disorders are the most significant contributor to pain and disability. Around 50% of the adult population experiences some sort of musculoskeletal symptoms and 40% has long-lasting problems. The years lived with disability worldwide, account for 149 million (17%) of all years.
Though musculoskeletal symptoms are amongst the most prevalent symptoms in primary care (29% of patients’ visits to primary care centres), the patient journey from symptom to diagnosis and treatment is often tenuous, long and frustrating. Between 13 and 35% of patients do not receive a diagnosis from their primary care physicians and rheumatologists misclassify 30% of patients at the first visit. Delays arising from not attending the correct clinic ranges from up to 1 year for arthritis to 8.5 years for spondyloarthropathy. Treatment occurs in a trial-and-error fashion, resulting in first line treatment failing in 60% of the patients.
Early identification of disease can prevent chronic pain in osteoarthritis and fibromyalgia. Immune mediated rheumatic diseases respond better to treatment, both short-term and long-term, when initiated early. Critically, a recent scientific breakthrough by SPIDeRR partner FAU suggests that the onset of rheumatoid arthritis can be prevented by timely treatment with abatacept. However, our healthcare system is not yet equipped to implement this as patients are often identified too late. A major problem in implementing early and precise therapy is the difficulty in distinguishing individuals with emerging immune-mediated rheumatic disease from the more numerous patients with other musculoskeletal disorders, which require different types of care.
In-depth
Approaches
Modular SPIDeRR
Stratification A (Figure 1) focuses on transferring existing knowledge into models for use by people who lack that knowledge.
Four datatypes are present:
- Serology and blood work-up
- Self reported symptoms from a questionnaire
- Clinical data from electronic health records (EHR)
- Primary care data
For each of the four data types present in data collection a classification algorithms will be trained outputting the probability that:
- A patient’s Musculoskeletal Complaints are due to a mechanical cause of rheumatic disease.
- Among those with a non-autoimmune mediated rheumatic disease, further stratification into osteoarthritis, fibromyalgia and gout.
This modular design allows for great flexibility; e.g. re-use of the algorithmic building blocks in different composition, making it amenable to the scenarios of varying patient routes. The resulting output of stratifications is a stepwise risk assessment that, with each addition of a diagnostic data resource, updates the probabilities for the possible outcomes. Depending on the accumulated evidence at each diagnostic step, a physician can decide whether there is a need to collect additional diagnostic data to make a reliable diagnosis.

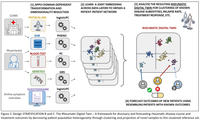
Digital Twin
At the level of the rheumatology clinic, and particularly amongst patients with auto-immune mediated rheumatic disease, the current knowledge on patient differentiation falls short - our clinical human brain fails to identify the complete pattern. With recurrent patterns in high dimensional data, made to efficiently exploit the growing body of data of previously diagnosed and treated patients, diagnostic and treatment recommendations will be inferred for new incoming patients.
Statements regarding disease trajectory are collected for new patients at different timepoints by matching them to highly similar patients in our ever-expanding historic data (their ‘Digital Twins’).
Using integrative deep neural networks patient information is co-embed across all relevant data domains to obtain so-called patient-patient similarity networks (Figure 2. [2]).
Stratification B - Disease subtype discovery
Data-driven grouping of patients will allow us to quantify differences in patient characteristics between participating member states. Do patient cluster prevalences differ across centres located in different member states? And do these data-driven patient groupings predict clinical outcomes better than canonical subtypes and/or known risk markers consistently?
Stratification C - Disease course modelling
The Digital Twin also provides a framework to interpret longitudinal data points; each visit will be separately embedded, as if it were a separate patient, thus adding a longitudinal component to the framework. Hence, patient clusters identified within this longitudinal Rheumatic Digital Twin (l-Rheumatic Digital Twin) might constitute disease subtypes, or different stages thereof, that arise during the disease-treatment course. An evaluation of longitudinal developments is made using the following concepts:
- Model the migration of patients across clusters during sequential visits using Markov Models.
- Infer a relative treatment-disease stage by mapping new patients to patient clusters in the l-Rheumatic Digital Twin that we have ranked by their relative time after-diagnosis.
- Evaluate intervention efficacy within each patient cluster by comparing the time spent under different treatment regimens.
- Previous steps will jointly inform the therapeutic window, i.e. the path of treatment-disease stages still susceptible to a therapeutic intervention, which will be apparent through a transition to a stage associated with a beneficial outcome.
SPIDeRR
Stratification of Patients using advanced Integrative modelling of Data Routinely acquired for diagnosing Rheumatic complaints
Funding
Follow us
Contact information

Albinusdreef 2